%20--%3e%3cdefs%3e%3cstyle%3e%20.st0%20{%20fill:%20%23061b40;%20}%20.st1%20{%20fill:%20%23306af1;%20}%20.st2%20{%20fill:%20%235ce5cf;%20}%20%3c/style%3e%3c/defs%3e%3cg%3e%3cpath%20class='st0'%20d='M55,10.5h9v3h-9v9h12V7.5h-12v3ZM64,19.5h-6v-3h6v3Z'/%3e%3cpolygon%20class='st0'%20points='69%2016.5%2078%2016.5%2078%2019.5%2069%2019.5%2069%2022.5%2081%2022.5%2081%2013.5%2072%2013.5%2072%2010.5%2081%2010.5%2081%207.5%2069%207.5%2069%2016.5'/%3e%3cpolygon%20class='st0'%20points='95%2010.5%2095%207.5%2083%207.5%2083%2022.5%2095%2022.5%2095%2019.5%2086%2019.5%2086%2016.5%2095%2016.5%2095%2013.5%2086%2013.5%2086%2010.5%2095%2010.5'/%3e%3cpath%20class='st0'%20d='M40,1.5v21h11.6l1.4-1.4v-7.6h0c0,0-1.4-1.5-1.4-1.5l1.4-1.4V2.9l-1.4-1.4h-11.6ZM50,19.5h-7v-6h7v6ZM50,10.5h-7v-6h7v6Z'/%3e%3c/g%3e%3cpath%20class='st1'%20d='M23.1,24L14.7,4.8l-4.9,11.2h3.8l-1.8,4H3.3L12.1,0H2C.9,0,0,.9,0,2v20c0,1.1.9,2,2,2h21.1Z'/%3e%3cpath%20class='st2'%20d='M34,0h-16.8l10.6,24h6.2c1.1,0,2-.9,2-2V2C36,.9,35.1,0,34,0ZM32.5,20h-4V4h4v16Z'/%3e%3c/svg%3e)
# Transformer Model
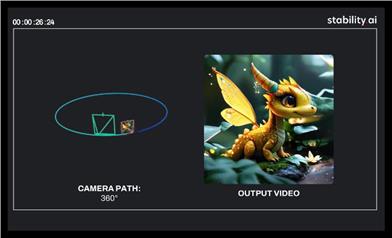
Stable Virtual Camera
Stable Virtual Camera is a 1.3B parameter general diffusion model developed by Stability AI, belonging to the Transformer image-to-video model. Its importance lies in providing technical support for novel view synthesis (NVS), capable of generating 3D-consistent new scene views based on input views and target cameras. The main advantages are the ability to freely specify the target camera trajectory, generate samples with large perspective changes that are smooth over time, maintain high consistency without additional neural radiance field (NeRF) distillation, and generate high-quality seamless loop videos up to half a minute long. The model is only freely available for research and non-commercial use, aiming to provide innovative image-to-video solutions for researchers and non-commercial creators.
Video Production
61.0K
Modernbert Base
ModernBERT-base is a modern bidirectional encoder Transformer model pretrained on 2 trillion English and code samples, natively supporting up to 8192 tokens of context. The model incorporates cutting-edge architectural improvements such as Rotary Positional Embeddings (RoPE), Local-Global Alternating Attention, and Unpadding, showing exceptional performance on long-text processing tasks. It is ideal for processing long documents for tasks such as retrieval, classification, and semantic search within large corpuses. Since the training data is primarily in English and code, its performance may be reduced when handling other languages.
AI Model
53.8K
LLNL/LUAR
LLNL/LUAR is a Transformer-based model designed for learning author representations, primarily focused on cross-domain transfer research for author verification. Introduced in an EMNLP 2021 paper, it explores whether author representations learned in one domain can be transferred to another. Key advantages of the model include its ability to handle large datasets and facilitate zero-shot transfer across diverse domains such as Amazon reviews, fanfiction short stories, and Reddit comments. Background information includes innovative research in the field of cross-domain author verification and its potential applications in natural language processing. This product is open-source and follows the Apache-2.0 license, allowing for free use.
Research Equipment
47.7K
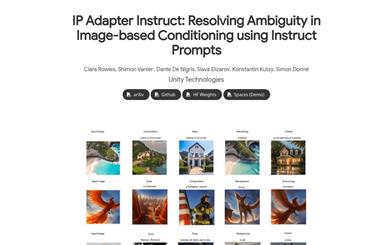
Ipadapter Instruct
IPAdapter-Instruct is an image generation model developed by Unity Technologies. It enhances a transformer model by adding extra text embedding conditions, allowing a single model to efficiently perform various image generation tasks. The primary advantage of this model lies in its ability to flexibly switch between different condition interpretations, such as style transfer and object extraction, using 'Instruct' prompts, while maintaining minimal quality loss compared to task-specific models.
AI image generation
65.4K
Genau
GenAU is an audio generation model developed by Snap Research. It leverages the AutoCap automatic captioning model and the GenAu audio generation architecture to significantly enhance audio quality. It excels in generating environmental sounds and effects, particularly in scenarios with limited data and subpar caption quality. The GenAU model is capable of producing high-quality audio and holds immense potential in the field of audio synthesis.
AI audio enhancer
54.1K
Videollama2 7B Base
VideoLLaMA2-7B-Base, developed by DAMO-NLP-SG, is a large video language model focused on understanding and generating video content. This model demonstrates exceptional performance in visual question answering and video captioning. Through advanced spatiotemporal modeling and audio understanding capabilities, it provides users with a new tool for analyzing video content. Based on the Transformer architecture, it can process multi-modal data, combining textual and visual information to generate accurate and insightful outputs.
AI video generation
78.7K

GRM
GRM is a large-scale reconstruction model that can recover 3D assets from sparse view images in 0.1 seconds and achieve generation in 8 seconds. It is a feed-forward Transformer-based model that can efficiently fuse multi-view information to convert input pixels into pixel-aligned Gaussian distributions. These Gaussian distributions can be back-projected into a dense 3D Gaussian distribution collection representing the scene. Our Transformer architecture and the use of 3D Gaussian distributions unlock a scalable and efficient reconstruction framework. Extensive experimental results demonstrate that our method surpasses other alternatives in terms of reconstruction quality and efficiency. We also showcase GRM's potential in generation tasks (such as text-to-3D and image-to-3D) by combining it with existing multi-view diffusion models.
AI image generation
62.4K
Featured AI Tools
English Picks

Jules AI
Jules は、自動で煩雑なコーディングタスクを処理し、あなたに核心的なコーディングに時間をかけることを可能にする異步コーディングエージェントです。その主な強みは GitHub との統合で、Pull Request(PR) を自動化し、テストを実行し、クラウド仮想マシン上でコードを検証することで、開発効率を大幅に向上させています。Jules はさまざまな開発者に適しており、特に忙しいチームには効果的にプロジェクトとコードの品質を管理する支援を行います。
開発プログラミング
49.1K

Nocode
NoCode はプログラミング経験を必要としないプラットフォームで、ユーザーが自然言語でアイデアを表現し、迅速にアプリケーションを生成することが可能です。これにより、開発の障壁を下げ、より多くの人が自身のアイデアを実現できるようになります。このプラットフォームはリアルタイムプレビュー機能とワンクリックデプロイ機能を提供しており、技術的な知識がないユーザーにも非常に使いやすい設計となっています。
開発プラットフォーム
45.3K

Listenhub
ListenHub は軽量級の AI ポッドキャストジェネレーターであり、中国語と英語に対応しています。最先端の AI 技術を使用し、ユーザーが興味を持つポッドキャストコンテンツを迅速に生成できます。その主な利点には、自然な会話と超高品質な音声効果が含まれており、いつでもどこでも高品質な聴覚体験を楽しむことができます。ListenHub はコンテンツ生成速度を改善するだけでなく、モバイルデバイスにも対応しており、さまざまな場面で使いやすいです。情報取得の高効率なツールとして位置づけられており、幅広いリスナーのニーズに応えています。
AI
43.1K
Chinese Picks

腾讯混元画像 2.0
腾讯混元画像 2.0 は腾讯が最新に発表したAI画像生成モデルで、生成スピードと画質が大幅に向上しました。超高圧縮倍率のエンコード?デコーダーと新しい拡散アーキテクチャを採用しており、画像生成速度はミリ秒級まで到達し、従来の時間のかかる生成を回避することが可能です。また、強化学習アルゴリズムと人間の美的知識の統合により、画像のリアリズムと詳細表現力を向上させ、デザイナー、クリエーターなどの専門ユーザーに適しています。
画像生成
43.6K

Openmemory MCP
OpenMemoryはオープンソースの個人向けメモリレイヤーで、大規模言語モデル(LLM)に私密でポータブルなメモリ管理を提供します。ユーザーはデータに対する完全な制御権を持ち、AIアプリケーションを作成する際も安全性を保つことができます。このプロジェクトはDocker、Python、Node.jsをサポートしており、開発者が個別化されたAI体験を行うのに適しています。また、個人情報を漏らすことなくAIを利用したいユーザーにお勧めします。
オープンソース
45.3K

Fastvlm
FastVLM は、視覚言語モデル向けに設計された効果的な視覚符号化モデルです。イノベーティブな FastViTHD ミックスドビジュアル符号化エンジンを使用することで、高解像度画像の符号化時間と出力されるトークンの数を削減し、モデルのスループットと精度を向上させました。FastVLM の主な位置付けは、開発者が強力な視覚言語処理機能を得られるように支援し、特に迅速なレスポンスが必要なモバイルデバイス上で優れたパフォーマンスを発揮します。
画像処理
43.1K
English Picks

ピカ
ピカは、ユーザーが自身の創造的なアイデアをアップロードすると、AIがそれに基づいた動画を自動生成する動画制作プラットフォームです。主な機能は、多様なアイデアからの動画生成、プロフェッショナルな動画効果、シンプルで使いやすい操作性です。無料トライアル方式を採用しており、クリエイターや動画愛好家をターゲットとしています。
映像制作
17.6M
Chinese Picks

Liblibai
LiblibAIは、中国をリードするAI創作プラットフォームです。強力なAI創作能力を提供し、クリエイターの創造性を支援します。プラットフォームは膨大な数の無料AI創作モデルを提供しており、ユーザーは検索してモデルを使用し、画像、テキスト、音声などの創作を行うことができます。また、ユーザーによる独自のAIモデルのトレーニングもサポートしています。幅広いクリエイターユーザーを対象としたプラットフォームとして、創作の機会を平等に提供し、クリエイティブ産業に貢献することで、誰もが創作の喜びを享受できるようにすることを目指しています。
AIモデル
6.9M